遅い SQL を前にしたとき、EXPLAIN ANALYZE を上から順に追い始めると、情報量の多さで迷いやすくなります。この記事の題材は customers と orders の最小デモです。sort / join / aggregate の 3 例を通して、Execution Time、actual time、rows、loops の順で詰まりどころを読む手順を整理します。既存の PostgreSQLのインデックス入門(B-tree と EXPLAIN ANALYZE の最小例) から一歩進めて、焦点は「どのノードが重いのか」の見つけ方に置きます。
前提環境
- Windows 11
- WSL2(Ubuntu)
- VS Code(Remote - WSL)
- Docker Desktop
- PostgreSQL 17
psql
以降のコマンドは、特記がない限り WSL 側ターミナルで実行します。
1. ゴールと非対象
到達する状態:
EXPLAIN ANALYZEを読む順番を固定できる- sort / join / aggregate の plan で、どのノードを先に見るか判断できる
rows/actual time/loopsを手掛かりに、次に疑うポイントを絞れる
扱わない内容:
- 実行計画の全ノード一覧
Bitmap Heap ScanやMerge Joinの詳細work_memや統計情報のチューニング手順pg_stat_statementsを使った本番監視
今回は「どう直すか」より先に、「どこが詰まっているかをどう読むか」に絞ります。
2. 最小デモ環境を作る
記事用の空ディレクトリを作ります。
mkdir -p ~/projects/postgresql-slow-query-explain-demo
cd ~/projects/postgresql-slow-query-explain-demo
mkdir -p sql
code .最終的な構成は次の 4 ファイルです。
postgresql-slow-query-explain-demo/
├─ compose.yml
├─ .env.example
└─ sql/
├─ 01-schema.sql
└─ 02-seed.sqlcompose.yml を作成し、次の内容を保存します。
services:
db:
image: postgres:17
working_dir: /workspace
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
ports:
- "5432:5432"
volumes:
- db-data:/var/lib/postgresql/data
- ./:/workspace
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"]
interval: 5s
timeout: 3s
retries: 20
volumes:
db-data:.env.example を作成し、次の内容を保存します。
POSTGRES_DB=app
POSTGRES_USER=app
POSTGRES_PASSWORD=app起動と確認は次のコマンドです。
cp .env.example .env
docker compose up -d
docker compose exec db pg_isready -U app -d app
docker compose exec db psql -U app -d app -c "SELECT version();"pg_isready が accepting connections を返せば準備完了です。
3. テーブルと seed を用意する
今回は customers と orders の 2 テーブルだけ使います。customers.segment は vip が少数、orders.status は new が少数になるようにして、join の例で loops が見やすい分布にします。
sql/01-schema.sql を作成し、次の内容を保存します。
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS customers;
CREATE TABLE customers (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name TEXT NOT NULL,
segment TEXT NOT NULL CHECK (segment IN ('general', 'vip'))
);
CREATE TABLE orders (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_id BIGINT NOT NULL REFERENCES customers(id),
status TEXT NOT NULL CHECK (status IN ('new', 'paid', 'shipped')),
total_cents INTEGER NOT NULL,
created_at TIMESTAMPTZ NOT NULL
);sql/02-seed.sql を作成し、次の内容を保存します。
TRUNCATE TABLE orders RESTART IDENTITY CASCADE;
TRUNCATE TABLE customers RESTART IDENTITY CASCADE;
INSERT INTO customers (name, segment)
SELECT
'customer-' || lpad(gs::text, 5, '0'),
CASE WHEN gs % 20 = 0 THEN 'vip' ELSE 'general' END
FROM generate_series(1, 10000) AS gs;
INSERT INTO orders (customer_id, status, total_cents, created_at)
SELECT
((gs - 1) % 10000) + 1,
CASE
WHEN gs % 10 = 0 THEN 'new'
WHEN gs % 10 IN (1, 2, 3, 4, 5, 6) THEN 'paid'
ELSE 'shipped'
END,
1000 + (gs % 5000),
TIMESTAMPTZ '2026-01-01 00:00:00+00' + (gs || ' seconds')::interval
FROM generate_series(1, 200000) AS gs;
ANALYZE customers;
ANALYZE orders;スキーマと seed を適用します。
docker compose exec db psql -U app -d app -f sql/01-schema.sql
docker compose exec db psql -U app -d app -f sql/02-seed.sql
docker compose exec db psql -U app -d app -c "SELECT segment, COUNT(*) FROM customers GROUP BY segment ORDER BY segment;"
docker compose exec db psql -U app -d app -c "SELECT status, COUNT(*) FROM orders GROUP BY status ORDER BY status;"期待する件数は次のとおりです。
| テーブル | 条件 | count |
|---|---|---|
| customers | segment = 'general' | 9500 |
| customers | segment = 'vip' | 500 |
| orders | status = 'new' | 20000 |
| orders | status = 'paid' | 120000 |
| orders | status = 'shipped' | 60000 |
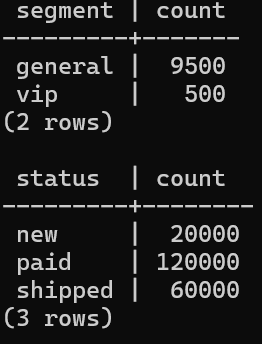
ANALYZE を入れているのは、PostgreSQL にデータ分布を知らせるためです。rows の見積もりが極端に外れると plan の読み方そのものがぶれやすくなるので、比較記事では先に統計情報を更新しておいたほうが追いやすくなります。
4. EXPLAIN ANALYZE はこの順で読む
この記事では、実行計画を次の順番で読みます。上から順に全部読むより、この順番のほうが詰まりどころを見つけやすくなります。
flowchart TD
A["Execution Time を見る"] --> B["actual time が大きいノードを見る"]
B --> C["rows の見積もりと実測を比べる"]
C --> D["loops で繰り返し回数を見る"]
D --> E["手前の Scan や Filter に戻る"]それぞれの見方は次のとおりです。
| 観点 | 見る場所 | 何が分かるか |
|---|---|---|
Execution Time | plan 末尾 | SQL 全体でどれくらい時間を使ったか |
actual time | 各ノード | そのノードが仕事を始めてから終えるまでの時間 |
rows | 各ノード | 何行処理した見込みか、実際に何行流れたか |
loops | 各ノード | そのノードが何回繰り返されたか |
補足しておくと、actual time=0.020..10.066 のような表示では、後ろの値が「そのノードが全行を出し終えた時点」に近い目安です。この後ろ側の数値を見て、どのノードが SQL 全体の時間を持っていっているかを確認します。
また、rows の見積もりと実測が大きく外れている場合は、インデックス設計だけでなく統計情報の古さも疑いどころになります。今回は説明を絞るため、rows / actual time / loops を主役にします。
5. sort で詰まるときは Sort ノードを見る
ORDER BY を含む SQL です。並び替え対象の行数が多いと、Sort ノードがそのまま重くなります。読みやすさのため、ここでは並列 plan を避ける設定を先に入れています。
docker compose exec db psql -U app -d app -c "SET max_parallel_workers_per_gather = 0; EXPLAIN (ANALYZE, BUFFERS) SELECT id, customer_id, total_cents, created_at FROM orders ORDER BY created_at DESC LIMIT 50;"実行計画の例は次のとおりです。
Limit (cost=10296.86..10296.98 rows=50 width=28) (actual time=42.280..42.285 rows=50 loops=1)
Buffers: shared hit=1656
-> Sort (cost=10296.86..10796.86 rows=200000 width=28) (actual time=42.278..42.280 rows=50 loops=1)
Sort Key: created_at DESC
Sort Method: top-N heapsort Memory: 32kB
Buffers: shared hit=1656
-> Seq Scan on orders (cost=0.00..3653.00 rows=200000 width=28) (actual time=0.006..15.982 rows=200000 loops=1)
Buffers: shared hit=1653
Planning Time: 0.350 ms
Execution Time: 42.316 msここで見たいのは次の 4 点です。
- SQL 全体の
Execution Timeが約 42 ms で、その大半がSortノードの完了時刻と近い Sortの入力rows=200000は orders テーブルの全行に相当するLIMIT 50が付いていても、その前に 20 万行を見て並び替えているSort Method: top-N heapsortは「上位 50 件だけ取りたい sort」の実装であり、sort が消えたわけではない
この plan では、重いのは Limit ではなく Sort です。さらに、その Sort が重い理由は手前の Seq Scan から 20 万行流れてきていることにあります。つまり「sort が遅い」と読んで終わりではなく、「何行を並び替えているか」まで戻る必要があります。
6. join では loops が効いてくる
join の plan では、ノード名だけでなく loops が急に重要になります。内側のノードが少し安く見えても、何百回も繰り返されると全体では無視できなくなるからです。
まず、Nested Loop を見やすくするために orders 側へインデックスを追加します。
docker compose exec db psql -U app -d app -c "CREATE INDEX idx_orders_customer_id_status ON orders (customer_id, status);"
docker compose exec db psql -U app -d app -c "ANALYZE orders;"そのうえで、vip 顧客と new 注文を join します。
docker compose exec db psql -U app -d app -c "SET max_parallel_workers_per_gather = 0; EXPLAIN (ANALYZE, BUFFERS) SELECT c.id, c.name, o.id FROM customers c JOIN orders o ON o.customer_id = c.id WHERE c.segment = 'vip' AND o.status = 'new';"実行計画の例は次のとおりです。
Nested Loop (cost=0.29..4254.85 rows=1005 width=31) (actual time=0.020..10.066 rows=10000 loops=1)
Buffers: shared hit=10879 read=195
-> Seq Scan on customers c (cost=0.00..199.00 rows=500 width=23) (actual time=0.009..0.777 rows=500 loops=1)
Filter: (segment = 'vip'::text)
Rows Removed by Filter: 9500
Buffers: shared hit=74
-> Index Scan using idx_orders_customer_id_status on orders o (cost=0.29..8.09 rows=2 width=16) (actual time=0.004..0.017 rows=20 loops=500)
Index Cond: ((customer_id = c.id) AND (status = 'new'::text))
Buffers: shared hit=10805 read=195
Planning Time: 0.530 ms
Execution Time: 10.398 msjoin で特に見たいのは、内側ノードの rows と loops です。
- 外側の
Seq Scan on customersはrows=500 loops=1で、vip顧客 500 人を取り出している - 内側の
Index Scanは 1 回あたりrows=20と軽く見える - ただし
loops=500なので、その軽いIndex Scanが 500 回繰り返されている - その結果、join 全体では 1 万行が返っている
rows=20 loops=500 を掛け合わせると、おおよそ 1 万行ぶんの仕事が内側で発生していると読めます。join の plan を見るときに Nested Loop という名前だけで判断すると、この繰り返しコストを見落としやすくなります。
この query 自体は 10 ms 台ですが、外側の行数がもっと増えたり、内側ノードが Index Scan ではなく重い Seq Scan だったりすると、一気に苦しくなります。join では「内側ノードが何回回るか」をまず確認すると、詰まりどころを追いやすくなります。
7. aggregate ではまとめる前の行数を見る
次は集約です。GROUP BY を含む SQL では、最終的に返る行数より前に、何行を集約に流し込んでいるかが効いてきます。
docker compose exec db psql -U app -d app -c "SET max_parallel_workers_per_gather = 0; EXPLAIN (ANALYZE, BUFFERS) SELECT customer_id, SUM(total_cents) AS total_sales FROM orders GROUP BY customer_id ORDER BY total_sales DESC LIMIT 10;"実行計画の例は次のとおりです。
Limit (cost=4968.24..4968.27 rows=10 width=16) (actual time=31.218..31.221 rows=10 loops=1)
Buffers: shared hit=1656
-> Sort (cost=4968.24..4993.18 rows=9973 width=16) (actual time=31.216..31.218 rows=10 loops=1)
Sort Key: (sum(total_cents)) DESC
Sort Method: top-N heapsort Memory: 25kB
Buffers: shared hit=1656
-> HashAggregate (cost=4653.00..4752.73 rows=9973 width=16) (actual time=29.810..30.510 rows=10000 loops=1)
Group Key: customer_id
Batches: 1 Memory Usage: 1169kB
Buffers: shared hit=1653
-> Seq Scan on orders (cost=0.00..3653.00 rows=200000 width=12) (actual time=0.006..9.495 rows=200000 loops=1)
Buffers: shared hit=1653
Planning Time: 0.189 ms
Execution Time: 31.512 msここでは Sort より先に HashAggregate を見ます。
HashAggregateが 20 万行を受け取り、1 万グループへまとめているactual time=29.810..30.510なので、SQL 全体 31.512 ms の大半をここが使っている- 最後の
Sortは 1 万グループを上位 10 件へ並べ替える仕上げで、集約本体とは役割が違う - 入力行数が大きいまま集約に入っているなら、先に絞れる条件がないかを疑いたくなる
aggregate の plan では、「最終的に 10 行しか返っていないから軽いはず」と考えないほうが安全です。重さは返り値の 10 行ではなく、その前段で 20 万行をまとめている部分にあります。
8. ノード別に次に疑うポイントを整理する
ここまでの 3 例を、次に見るポイントごとにまとめると次のようになります。
| ノード | まず見るもの | 今回の例で見えたこと | 次に疑うポイント |
|---|---|---|---|
Sort | actual time と入力 rows | 20 万行を並び替えていた | ORDER BY 列のインデックス、sort 前に件数を絞れないか |
Nested Loop | 内側ノードの rows と loops | rows=20 loops=500 だった | 外側の件数が多すぎないか、内側参照を軽くできないか |
HashAggregate | 集約前の入力 rows | 20 万行を 1 万グループにまとめていた | 集約前に filter できないか、グループ粒度が妥当か |
rows の見積もりが実測から大きく外れている場合は、インデックス不足だけでなく統計情報も候補になります。今回の例では見積もりと実測が極端にはずれていないため、ノードの役割そのものに集中して読めました。
9. まとめ
EXPLAIN ANALYZE は、上から順に全部読むより、まず Execution Time、次に重いノードの actual time、その次に rows、最後に loops を見るほうが詰まりどころを見つけやすくなります。sort では「何行を並び替えているか」、join では「内側ノードが何回回るか」、aggregate では「何行をまとめているか」が読む手掛かりになる。ここを押さえるだけでも、次に疑う場所は絞れます。
インデックスの基本から確認したい場合は PostgreSQLのインデックス入門(B-tree と EXPLAIN ANALYZE の最小例)、更新系 SQL とロックの見方へ進みたい場合は PostgreSQLのトランザクション入門(BEGIN / COMMIT / ROLLBACK と同時更新) や PHP + PostgreSQLで在庫引当を安全に実装する(SELECT … FOR UPDATE 最小構成) も続けて読むとつながります。