Mermaid の erDiagram を先に作り、そこから PostgreSQL の最小 CREATE TABLE に落とし込む手順を、customers / orders / order_items / products の 4 表で進めます。最後は psql の \d と JOIN で、図と SQL が同じ関係を表しているかまで確認します。
特定のプログラミング言語や ORM は対象外です。再現範囲は Docker + PostgreSQL + psql だけに絞ります。
前提環境
- Windows 11
- WSL2(Ubuntu)
- VS Code(Remote - WSL)
- Docker Desktop
- PostgreSQL 17
psql
以降のコマンドは、特記がない限り WSL 側ターミナルで実行します。
1. ゴールと非対象
到達する状態:
- 小さな業務要件から Mermaid の ER 図を作れる
- ER 図を PostgreSQL の 4 つの
CREATE TABLEに落とせる psqlの\dとJOINで、主キーと外部キーの関係を確認できる
扱わない内容:
- PHP や ORM からの利用
ON DELETE CASCADE/RESTRICT/SET NULLの比較UNIQUE/CHECK/ index の深掘り- 正規化理論の体系的な説明
- 本番運用の権限設計やバックアップ
今回は「最初のテーブルの切り方」に集中します。削除ルールや制約強化は、後続のテーマとして切り分けます。
2. 最小デモ環境を作る
作業用の空ディレクトリを作ります。
mkdir -p ~/projects/postgresql-er-diagram-create-table-minimal-demo
cd ~/projects/postgresql-er-diagram-create-table-minimal-demo
mkdir -p sql
code .最終的な構成は次の 3 ファイルです。
postgresql-er-diagram-create-table-minimal-demo/
├─ compose.yml
├─ .env.example
└─ sql/
├─ 01-schema.sql
└─ 02-seed.sqlcompose.yml を作成します。
services:
db:
image: postgres:17
working_dir: /workspace
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
ports:
- "5432:5432"
volumes:
- db-data:/var/lib/postgresql/data
- ./:/workspace
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"]
interval: 5s
timeout: 3s
retries: 20
volumes:
db-data:今回はアプリケーションコンテナを足しません。db サービスだけにしておくと、psql と SQL ファイルだけで最後まで進められます。
.env.example を作成します。
POSTGRES_DB=app
POSTGRES_USER=app
POSTGRES_PASSWORD=app起動します。
cp .env.example .env
docker compose up -d
docker compose exec db pg_isready -U app -d app
docker compose exec db psql -U app -d app -c "SELECT version();"確認ポイント:
pg_isreadyがaccepting connectionsを返すSELECT version();が 1 行返る
詰まったとき:
docker compose logs db
docker compose down -v3. 小さな業務要件を Mermaid の ER 図にする
今回は、次の業務要件を題材にします。
- 顧客は複数の注文を持てる
- 1 つの注文は必ず 1 人の顧客にひも付く
- 1 つの注文には複数の商品を入れられる
- 同じ商品は複数の注文に登場できる
- 注文時の単価は、商品マスタの現在価格とは分けて持つ
- 数量は今回は整数だけを扱う
この要件を Mermaid で図にすると、次の形になります。
erDiagram
CUSTOMERS ||--o{ ORDERS : places
ORDERS ||--o{ ORDER_ITEMS : has
PRODUCTS ||--o{ ORDER_ITEMS : appears_in
CUSTOMERS {
bigint id PK
text customer_name
}
ORDERS {
bigint id PK
bigint customer_id FK
}
PRODUCTS {
bigint id PK
text product_name
integer price
}
ORDER_ITEMS {
bigint id PK
bigint order_id FK
bigint product_id FK
integer quantity
integer unit_price
}orders と products を直接つながず、order_items を挟んでいる理由は 2 つあります。
- 1 つの注文に複数の商品を入れられ、同じ商品も複数注文に登場するので、多対多の関係になる
- 今回は「何個買ったか」と「注文時の単価」も持ちたいので、単なる結合用テーブルではなく注文明細テーブルとして独立させる必要がある
この図を見ると、customers と orders は 1 対多です。
そのため外部キーは customers 側ではなく、複数側の orders に customer_id として置きます。
4. ER 図を CREATE TABLE に落とす
いきなり CREATE TABLE 全文へ進む前に、図をいったん列の草案へ落とします。
| テーブル | まず置く列 |
|---|---|
customers | id, customer_name |
products | id, product_name, price |
orders | id, customer_id |
order_items | id, order_id, product_id, quantity, unit_price |
この対応表を挟むと、Mermaid の線と CREATE TABLE の列の対応を追いやすくなります。
sql/01-schema.sql を作成します。
CREATE TABLE customers (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_name TEXT NOT NULL
);
CREATE TABLE products (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
product_name TEXT NOT NULL,
price INTEGER NOT NULL
);
CREATE TABLE orders (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_id BIGINT NOT NULL REFERENCES customers(id)
);
CREATE TABLE order_items (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
order_id BIGINT NOT NULL REFERENCES orders(id),
product_id BIGINT NOT NULL REFERENCES products(id),
quantity INTEGER NOT NULL,
unit_price INTEGER NOT NULL
);ここでの判断は次のとおりです。
- 主キーは全表で
BIGINT GENERATED ALWAYS AS IDENTITYに統一する orders.customer_id、order_items.order_id、order_items.product_idが外部キーになるcustomer_nameとproduct_nameは必須項目なのでNOT NULLにするpriceは商品マスタの現在価格、unit_priceは注文時点の価格スナップショットとして分けるquantityは今回は整数だけを扱うのでINTEGERにする- 金額も今回は日本円の整数前提にして
INTEGERにする
order_items は (order_id, product_id) の複合主キーではなく、単一の surrogate key を採用しています。
これは「複合主キーを知らないから省いた」のではなく、最小構成に集中するための判断です。重複防止の UNIQUE や複合主キーは、制約を扱う回で追加します。
コードのポイント
CREATE TABLE customers (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_name TEXT NOT NULL
);
CREATE TABLE products (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
product_name TEXT NOT NULL,
price INTEGER NOT NULL
);
CREATE TABLE orders (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_id BIGINT NOT NULL REFERENCES customers(id)
);
CREATE TABLE order_items (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
order_id BIGINT NOT NULL REFERENCES orders(id),
product_id BIGINT NOT NULL REFERENCES products(id),
quantity INTEGER NOT NULL,
unit_price INTEGER NOT NULL
);- 14行目
customer_id BIGINT NOT NULL REFERENCES customers(id)— 1 対多の「多」側に外部キーを置く。customers側に列を足す形と比べ、顧客が複数注文を持てる構造を自然に表せる。Mermaid のCUSTOMERS ||--o{ ORDERSの線がここに対応する。 - 19〜20行目
order_idとproduct_id—order_itemsがordersとproductsの両方を外部キーで参照することで、多対多の関係を中間テーブルとして表現する。2 本の FK が Mermaid の 2 本の線に対応する。 - 22行目
unit_price INTEGER NOT NULL—products.priceとは別の列として注文明細に持つ。注文時点の価格スナップショットで、商品マスタの価格が後から変わっても過去の注文金額に影響しない。
5. スキーマを適用してテーブル関係を確認する
4 章の SQL を sql/01-schema.sql として保存したら、psql で流します。
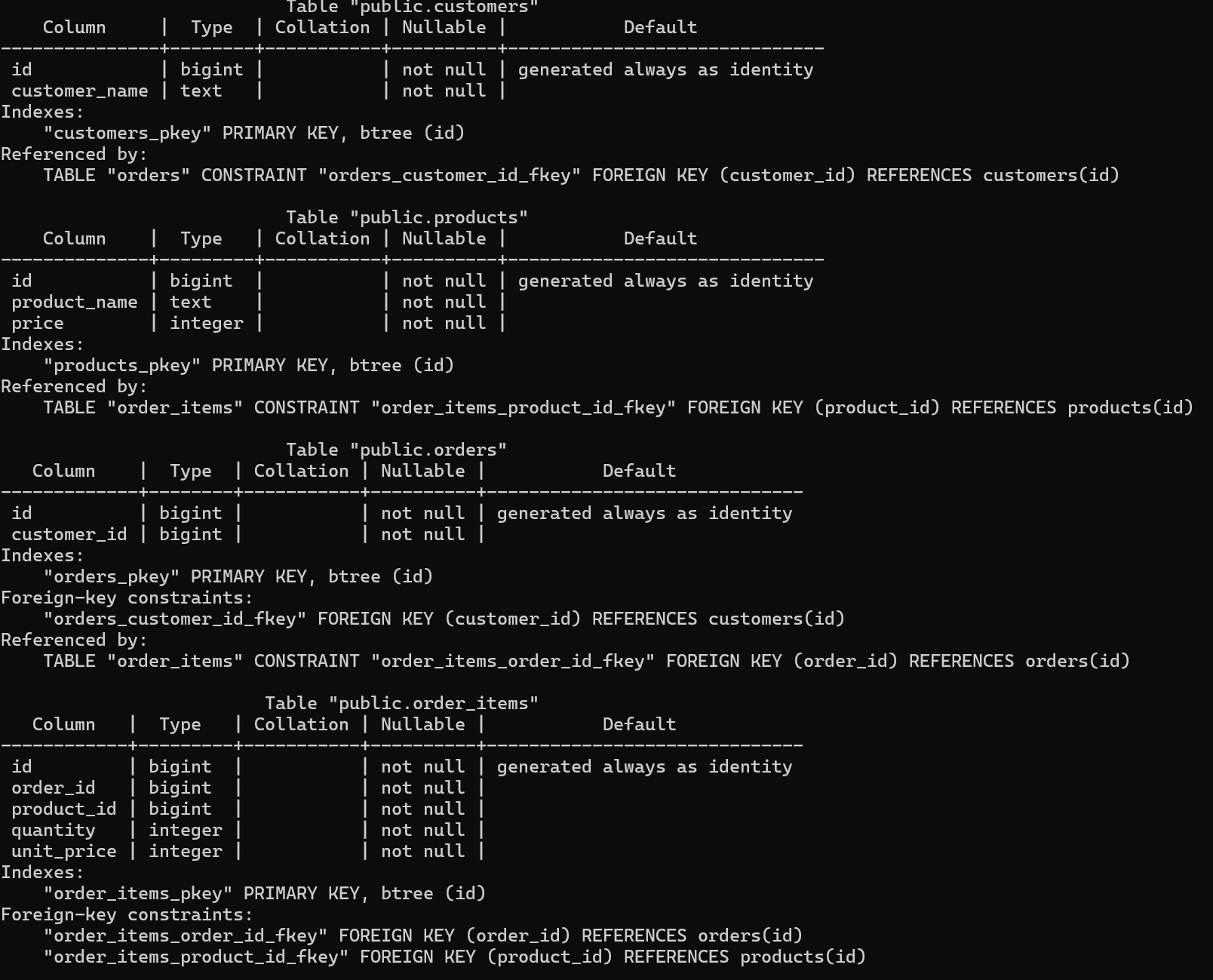
docker compose exec db psql -U app -d app -f sql/01-schema.sql続いて、各テーブル定義を \d で確認します。
docker compose exec db psql -U app -d app -c "\\d customers"
docker compose exec db psql -U app -d app -c "\\d products"
docker compose exec db psql -U app -d app -c "\\d orders"
docker compose exec db psql -U app -d app -c "\\d order_items"確認する点は次の 3 つです。
- 4 表すべてに
idの主キーがあるか orders.customer_idがcustomers(id)を参照しているかorder_items.order_idとorder_items.product_idが、それぞれorders(id)とproducts(id)を参照しているか
Mermaid の線は、PostgreSQL 上ではこの外部キー定義として現れます。
図と SQL がつながっているかを見るには、CREATE TABLE の文面だけより \d のほうが追いやすいです。
もし relation "customers" already exists のようなエラーが出たら、一度データボリュームを消してやり直してください。
docker compose down -v
docker compose up -d
docker compose exec db psql -U app -d app -f sql/01-schema.sql6. サンプルデータと JOIN で関係を確認する
次はデータを入れて、JOIN で期待通りの結果が返るかを確認します。sql/02-seed.sql を次の内容で作成します。
INSERT INTO customers (customer_name)
VALUES
('佐藤商店'),
('青山カフェ');
INSERT INTO products (product_name, price)
VALUES
('ノートPC', 120000),
('USB-Cドック', 19000),
('27インチモニター', 42000);
INSERT INTO orders (customer_id)
VALUES
(1),
(1),
(2);
INSERT INTO order_items (order_id, product_id, quantity, unit_price)
VALUES
(1, 1, 1, 120000),
(1, 2, 2, 18000),
(2, 3, 1, 42000),
(3, 2, 1, 17500);ここでは products.price と order_items.unit_price をあえて少しずらしています。
USB-Cドック の現在価格は 19000 円ですが、過去注文では 18000 円や 17500 円で売られた、という状態です。
データを投入します。
docker compose exec db psql -U app -d app -f sql/02-seed.sql確認には次の JOIN を使います。
SELECT
c.customer_name,
o.id AS order_id,
p.product_name,
oi.quantity,
oi.unit_price
FROM orders AS o
JOIN customers AS c
ON c.id = o.customer_id
JOIN order_items AS oi
ON oi.order_id = o.id
JOIN products AS p
ON p.id = oi.product_id
ORDER BY o.id, oi.id;psql から実行するなら、次のコマンドです。
docker compose exec db psql -U app -d app -c "SELECT c.customer_name, o.id AS order_id, p.product_name, oi.quantity, oi.unit_price FROM orders AS o JOIN customers AS c ON c.id = o.customer_id JOIN order_items AS oi ON oi.order_id = o.id JOIN products AS p ON p.id = oi.product_id ORDER BY o.id, oi.id;"期待する結果は次の表になります。
| 顧客名 | 注文ID | 商品名 | 数量 | 注文時単価 |
|---|---|---|---|---|
| 佐藤商店 | 1 | ノートPC | 1 | 120000 |
| 佐藤商店 | 1 | USB-Cドック | 2 | 18000 |
| 佐藤商店 | 2 | 27インチモニター | 1 | 42000 |
| 青山カフェ | 3 | USB-Cドック | 1 | 17500 |
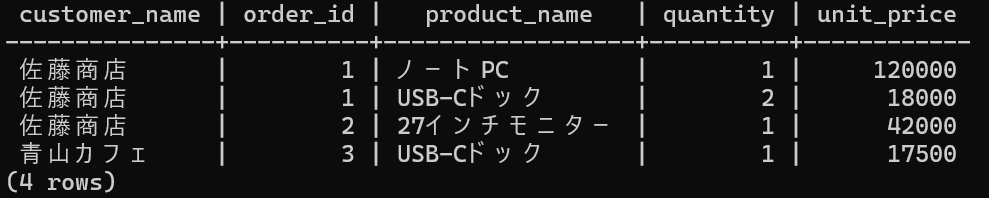
この結果を見ると、orders と products を直接つないでいない理由がはっきりします。
1 つの注文に複数商品が入り、同じ商品も別注文に登場し、そのたびに数量や注文時単価が変わるからです。そうした情報を持つ場所が order_items です。
コードのポイント
SELECT
c.customer_name,
o.id AS order_id,
p.product_name,
oi.quantity,
oi.unit_price
FROM orders AS o
JOIN customers AS c
ON c.id = o.customer_id
JOIN order_items AS oi
ON oi.order_id = o.id
JOIN products AS p
ON p.id = oi.product_id
ORDER BY o.id, oi.id;- 6行目
oi.unit_price—p.priceではなくorder_itemsの列を参照する。注文時点の価格スナップショットを使うため、商品マスタの現在価格が変わっても過去の注文金額には影響しない。 - 10〜11行目
JOIN order_items ON oi.order_id = o.id—ordersからproductsへ直接 JOIN するのではなくorder_itemsを経由する。Mermaid のORDERS ||--o{ ORDER_ITEMSの線がここに対応する。 - 12〜13行目
JOIN products ON p.id = oi.product_id—order_items.product_idを通じて商品マスタに到達する。Mermaid のPRODUCTS ||--o{ ORDER_ITEMSの線に対応する。
7. 最小構成で意図的に外したものを整理する
今回は「最初にどう切るか」に集中するため、次の項目はあえて外しています。
| 今回入れたもの | 今回外したもの | 今回外した理由 | 次に足す候補 |
|---|---|---|---|
| 主キー | ON DELETE | 削除時の業務ルールは要件依存が強い | CASCADE / RESTRICT / SET NULL の比較 |
| 外部キー | UNIQUE | order_items の重複防止は制約の話に入る | (order_id, product_id) の一意制約 |
NOT NULL | CHECK | 今回は数量や金額の型までに絞る | quantity > 0 などの検証 |
| 基本型 | index | 4 表の最初の切り方を先に固めたい | JOIN や検索条件に応じた index |
特に ON DELETE は、customers を消せるのか、orders を論理削除にするのかで結論が変わります。
最初の 1 本で機械的に CASCADE を入れるより、ここでは外部キーの向きだけ確実に押さえるほうが先です。
8. まとめ
今回やったことは次の 3 つです。
- 小さな業務要件を Mermaid の ER 図へ落とした
- ER 図から列草案を経由して PostgreSQL の
CREATE TABLEへ翻訳した psqlの\dとJOINで、図と SQL が同じ関係を表していることを確認した
Mermaid を最初に固定しておくと、「どの表に外部キーを置くか」「注文明細としてどの列を持たせるか」を図から逆算しやすくなります。
次の一歩としては、UNIQUE / CHECK / FOREIGN KEY の役割を整理したいなら PostgreSQLの制約入門(PRIMARY KEY / UNIQUE / CHECK / FOREIGN KEY)、ON DELETE の削除ルールに進みたいなら PostgreSQLの外部キーと削除ルールを整理する(CASCADE / RESTRICT / SET NULL) が取り組みやすいでしょう。アプリケーションコードまでつなげたいなら、WSL2 + Docker + PHP + PostgreSQLで最小CRUDを作る に進むと接続しやすくなります。