Ollama のローカル API を PHP から呼び、JSON 応答から本文を取り出すまでの最小構成を作ります。
モデルは qwen3.5:4b、エンドポイントは POST /api/generate、ストリーミングは無効(stream:false)に固定します。
外部 API キーや従量課金は使いません。 streaming、structured outputs、複数ターン会話、フレームワーク統合、RAG は扱いません。 確認は CLI スクリプトまでで完結し、ブラウザ UI は持ち込みません。
前提環境
- Windows 11
- WSL2(Ubuntu)
- VS Code(Remote - WSL)
- Docker Desktop(WSL 連携有効)
- Ollama(ホスト側にインストール済み)
以降のコマンドは、次のように使い分けます。
ollama --versionollama pullollama listとホスト側 API 確認は Windows 側の PowerShelldocker compose ...と PHP スクリプト実行は WSL 側ターミナル
Ollama をホスト側へ入れる前提なので、WSL 側に ollama コマンドがなくても問題ありません。
1. ゴールと非対象
到達する状態:
- Ollama のローカル API(
POST /api/generate)を PHP から 1 回呼べる - JSON 応答から
responseフィールドを取り出して表示できる - 接続失敗、タイムアウト、HTTP エラー、JSON 破損を分岐できる
扱わない内容:
stream:trueのストリーミング受信format: "json"や JSON Schema を使う structured outputs- 複数ターン会話や履歴管理
- Laravel / Slim / Symfony への組み込み
- 埋め込み、RAG、ベクトル DB
- OpenAI などクラウド API との切り替え
今回使うモデルは qwen3.5:4b です。最近の Qwen 系で、Ollama 公式 library に軽量 4B タグがあり、最小構成の記事に載せやすいため採用しました。
2. Ollama と Qwen モデルを用意する
PHP を書く前に、ローカル側で Ollama とモデルを準備します。 先にモデルを用意しておくと、あとで PHP 側のエラーと推論環境の問題を切り分けやすくなります。
Ollama の導入確認
ここからのコマンドは Windows 側の PowerShell で実行します。
Ollama がインストール済みであることを確認します。
ollama --versionバージョンが表示されれば準備完了です。 未導入の場合は Ollama 公式サイト からインストールしてください。
モデルの取得
qwen3.5:4b を pull します。約 3.4GB のダウンロードになるため、初回は少し時間がかかります。
ollama pull qwen3.5:4b完了したら、モデルが取得されていることを確認します。
ollama list一覧に qwen3.5:4b が表示されれば準備完了です。

qwen3.5:4b は Ollama library の qwen3.5 ページに掲載されているタグの 1 つです。正確な実体を確認したい場合は、同ページの tags 一覧から確認できます。
Ollama の詳細設定をいじっている場合
最小構成の確認中は、Ollama の詳細設定や環境変数をできるだけ増やさないほうが切り分けしやすくなります。
特に GUI や環境変数でコンテキスト長を大きい値に固定すると、qwen3.5:4b の初回ロードや推論がかなり重くなり、API 確認の段階で「反応がない」ように見えることがあります。
最初の確認では既定値のまま進めるか、必要になった時点でリクエストごとに options.num_ctx を渡すほうが安全です。
ホストアドレスや同時実行数の設定は、今回の単発確認では大きな問題になりにくい項目です。
3. ホスト側でローカル API を先に確認する
PHP を書く前に、Ollama のローカル API が単体で動くことを確認します。 ここは PHP 実装ではなく、API の疎通確認です。
qwen3.5 は thinking 対応モデルで、Ollama の API では thinking が既定で有効です。
本記事では reasoning trace を扱わず response だけを取り出したいので、request body に think:false を明示します。
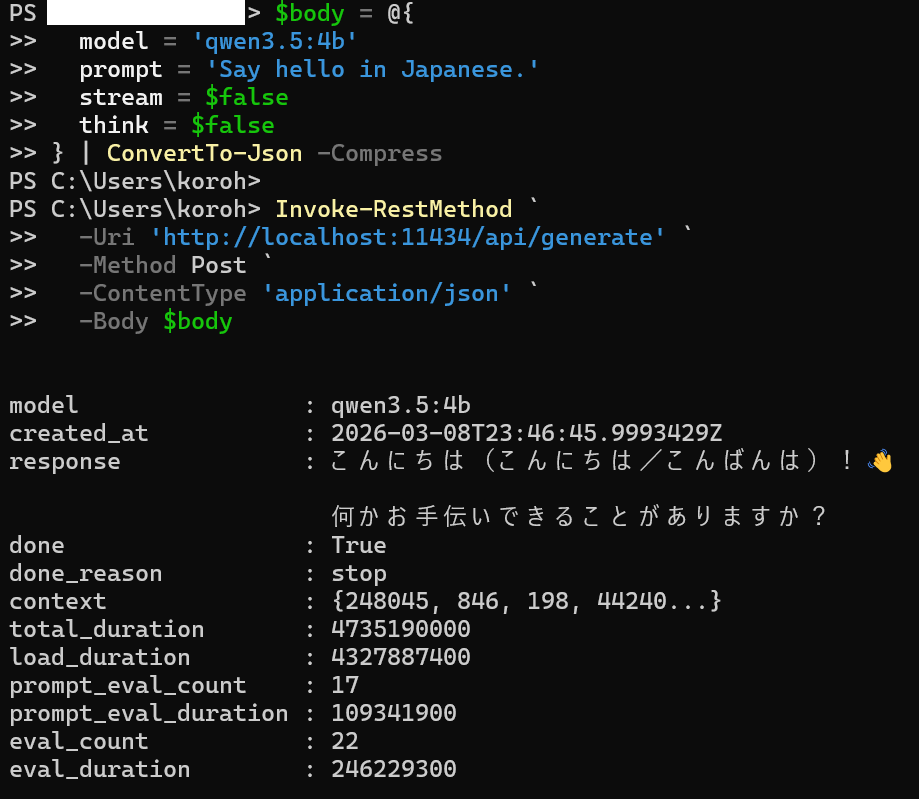
ホスト側(WSL ではなく Windows 側)の PowerShell から、Invoke-RestMethod で API を叩きます。
PowerShell では curl.exe に JSON を渡したときの引用ルールで詰まることがあるため、ここでは PowerShell 純正のコマンドレットを主線にします。
$body = @{
model = 'qwen3.5:4b'
prompt = 'Say hello in Japanese.'
stream = $false
think = $false
} | ConvertTo-Json -Compress
Invoke-RestMethod `
-Uri 'http://localhost:11434/api/generate' `
-Method Post `
-ContentType 'application/json' `
-Body $body成功すると、以下のような単一 JSON オブジェクトが返ります。
{
"model": "qwen3.5:4b",
"response": "こんにちは! (Konnichiwa!) ...",
"done": true,
"done_reason": "stop",
"total_duration": 1234567890
}response フィールドにモデルの出力が入っています。
stream:false にしているため、応答が分割されず単一の JSON として返ります。最小構成では ndjson より単一 JSON のほうが扱いやすいためです。
また think:false にしているため、thinking 用の追加フィールドを前提にした分岐を入れずに済みます。
ここでは localhost を使っていますが、後の手順でコンテナ内の PHP から呼ぶ際は host.docker.internal を使います。
疎通確認で詰まった場合
- 接続拒否: Ollama が起動しているか確認してください。
ollama serveで手動起動できます。 model not found:ollama pull qwen3.5:4bが完了しているか確認してください。- 応答が分割される:
stream:falseが request body に含まれているか確認してください。 - thinking の扱いが増えて混乱する:
think:falseが request body に含まれているか確認してください。 invalid character ... looking for beginning of object key string: PowerShell からcurl.exeへ JSON を渡すときに body が崩れている可能性があります。Invoke-RestMethodの例をそのまま使って確認してください。- 初回応答がかなり遅い: CPU 実行や初回ロードでは数分かかることがあります。配線確認だけ先に済ませたい場合は、一時的に
qwen3.5:0.8bかqwen3.5:2bへ切り替えて疎通確認し、最後にqwen3.5:4bへ戻すと切り分けしやすくなります。 - GUI の設定では動くのに API 確認だけ極端に遅い: GUI や環境変数でコンテキスト長を大きく固定していないか確認してください。最小構成の確認では既定値のままにするほうが安定します。
4. PHP デモ環境を作る
以後の手順を docker compose exec app php ... に統一するため、PHP の最小実行環境を用意します。
この段階ではまだ Ollama へは呼ばず、PHP の実行基盤だけを整えます。
新規デモディレクトリの作成
mkdir -p ~/projects/php-local-llm-ollama-demo
cd ~/projects/php-local-llm-ollama-demo
mkdir -p docker/php scripts src
code .compose.yml
services:
app:
build:
context: .
dockerfile: docker/php/Dockerfile
working_dir: /workspace
volumes:
- ./:/workspace
command: ["sleep", "infinity"]docker/php/Dockerfile
HTTP 呼び出しに ext-curl を使うため、Dockerfile で curl 拡張を入れます。
FROM php:8.5-cli
RUN apt-get update \
&& apt-get install -y --no-install-recommends unzip libcurl4-openssl-dev \
&& docker-php-ext-install curl \
&& rm -rf /var/lib/apt/lists/*
COPY --from=composer:2 /usr/bin/composer /usr/bin/composer
WORKDIR /workspacecomposer.json
{
"name": "demo/php-local-llm-ollama",
"type": "project",
"require": {
"php": ">=8.2"
},
"autoload": {
"psr-4": {
"App\\": "src/"
}
}
}コンテナのビルドと起動
docker compose up -d --buildphpdotenv のインストール
.env 読み込みは PHP 側で完結させたいので、vlucas/phpdotenv を使います。
docker compose exec app composer require vlucas/phpdotenv動作確認
docker compose exec app php -v
docker compose exec app composer --version
docker compose exec app php -m | grep curlphp -m | grep curl で curl が表示されれば、HTTP 呼び出しの準備は整っています。
詰まった場合
- Dockerfile を修正したら
docker compose up -d --buildで再ビルドが必要です。 curl拡張が見えない場合はコンテナを再ビルドしてください。- Composer の依存取得に失敗する場合は、コンテナ内からネットワークに出られるか確認してください。
5. .env と最小クライアントを作る
接続先 URL、モデル名、タイムアウトをコードから分離し、OllamaClient クラスに閉じ込めます。
.env.example
ホストで動く Ollama をコンテナから呼ぶため、OLLAMA_BASE_URL は http://host.docker.internal:11434/api を指定します。
OLLAMA_BASE_URL=http://host.docker.internal:11434/api
OLLAMA_MODEL=qwen3.5:4b
OLLAMA_TIMEOUT_SECONDS=120.env.example をコピーして .env を作成してください。
cp .env.example .envsrc/OllamaClient.php
cURL で Ollama の generate エンドポイントを呼び、response フィールドだけを取り出すクラスです。接続・タイムアウト・JSON 検証をこのクラスに閉じ込め、呼び出し側はプロンプト文字列を渡すだけで済む構成にしています。
<?php
declare(strict_types=1);
namespace App;
final class OllamaClient
{
public function __construct(
private readonly string $baseUrl,
private readonly string $model,
private readonly int $timeoutSeconds,
) {}
/**
* @return array{response: string, raw: array<string, mixed>}
* @throws \RuntimeException
*/
public function generate(string $prompt): array
{
$url = rtrim($this->baseUrl, '/') . '/generate';
$payload = json_encode([
'model' => $this->model,
'prompt' => $prompt,
'stream' => false,
'think' => false,
], JSON_THROW_ON_ERROR);
$ch = curl_init($url);
if ($ch === false) {
throw new \RuntimeException("curl_init failed for {$url}");
}
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_POSTFIELDS => $payload,
CURLOPT_HTTPHEADER => ['Content-Type: application/json'],
CURLOPT_RETURNTRANSFER => true,
CURLOPT_CONNECTTIMEOUT => 10,
CURLOPT_TIMEOUT => $this->timeoutSeconds,
]);
$body = curl_exec($ch);
if (curl_errno($ch) !== 0) {
$error = curl_error($ch);
throw new \RuntimeException("cURL error: {$error}");
}
if (!is_string($body)) {
throw new \RuntimeException('Empty response body from Ollama API');
}
$statusCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($statusCode !== 200) {
throw new \RuntimeException("HTTP {$statusCode} from {$url}");
}
try {
/** @var array<string, mixed> $data */
$data = json_decode($body, true, 512, JSON_THROW_ON_ERROR);
} catch (\JsonException $e) {
throw new \RuntimeException("JSON decode failed: {$e->getMessage()}");
}
if (!isset($data['response']) || !is_string($data['response'])) {
throw new \RuntimeException("'response' key missing or invalid in API response");
}
return [
'response' => $data['response'],
'raw' => $data,
];
}
}stream:false と think:false を request body に固定しているため、戻り値は「単一 JSON で final answer を受け取る」流れに寄せています。
エラーメッセージには生のプロンプト全文を含めず、HTTP ステータスや接続先だけを残しています。プロンプトが機微情報を含む場合に備えた配慮です。
詰まった場合
host.docker.internalをlocalhostのままにしていないか確認してください。コンテナ内のlocalhostはコンテナ自身を指します。- Docker Desktop 前提のため、Linux サーバー上の素の Docker Engine では
host.docker.internalがそのまま使えない場合があります。 .envを.env.exampleから作成したか確認してください。JSON_THROW_ON_ERRORで例外が出る場合は、受信した body が JSON でない可能性があります。3 章のホスト側確認に戻って API の応答を確認してください。
コードのポイント
① stream:false / think:false と JSON_THROW_ON_ERROR
stream:false を付けないと応答が ndjson(1 トークンずつの改行区切り JSON)になり、単一 JSON として受け取れません。think:false は reasoning trace を無効にし、response だけで完結するレスポンスに固定します。JSON_THROW_ON_ERROR でエンコード失敗を例外に変換しています。
$payload = json_encode([
'model' => $this->model,
'prompt' => $prompt,
'stream' => false,
'think' => false,
], JSON_THROW_ON_ERROR);② CURLOPT_RETURNTRANSFER と CURLOPT_TIMEOUT
CURLOPT_RETURNTRANSFER => true がないと curl_exec は結果を直接出力して true を返すため、後続の JSON デコードができません。CURLOPT_TIMEOUT には .env の値を使い、モデルの読み込み時間に応じて調整できる構成にしています。
curl_setopt_array($ch, [
CURLOPT_POST => true,
CURLOPT_POSTFIELDS => $payload,
CURLOPT_HTTPHEADER => ['Content-Type: application/json'],
CURLOPT_RETURNTRANSFER => true,
CURLOPT_CONNECTTIMEOUT => 10,
CURLOPT_TIMEOUT => $this->timeoutSeconds,
]);③ $data['response'] の型チェック
JSON デコードが成功しても response キーが存在しない、または文字列でない場合があります。stream:false の付け忘れで ndjson が返ってきたときも response の構造が変わるため、取り出し前に isset と is_string で確認しています。
if (!isset($data['response']) || !is_string($data['response'])) {
throw new \RuntimeException("'response' key missing or invalid in API response");
}6. PHP から 1 回呼んで応答を表示する
OllamaClient を CLI スクリプトから呼び、「PHP からローカル LLM を呼ぶ」を完結させます。
scripts/chat.php
コマンドライン引数でプロンプトを受け取り、OllamaClient に渡して応答を標準出力へ表示するスクリプトです。
<?php
declare(strict_types=1);
require_once __DIR__ . '/../vendor/autoload.php';
use App\OllamaClient;
use Dotenv\Dotenv;
$dotenv = Dotenv::createImmutable(__DIR__ . '/..');
$dotenv->load();
$prompt = $argv[1] ?? null;
if ($prompt === null) {
fwrite(STDERR, "Usage: php scripts/chat.php \"your prompt here\"\n");
exit(1);
}
$client = new OllamaClient(
baseUrl: $_ENV['OLLAMA_BASE_URL'],
model: $_ENV['OLLAMA_MODEL'],
timeoutSeconds: (int) $_ENV['OLLAMA_TIMEOUT_SECONDS'],
);
try {
$result = $client->generate($prompt);
echo $result['response'] . "\n";
} catch (\RuntimeException $e) {
fwrite(STDERR, "Error: {$e->getMessage()}\n");
exit(1);
}実行
docker compose exec app php scripts/chat.php "PHPの特徴を1文で教えてください。"成功すると、モデルの応答本文だけが表示されます。
PHPはサーバーサイドで動作するスクリプト言語で、Webアプリケーション開発に広く使われています。実際の応答内容はモデルの推論によって毎回変わります。 1 回目の実行はモデルの読み込みで待つことがあります。2 回目以降は速くなるのが通常です。

prompt を 1 引数で受けるだけにしています。複数ターン会話や履歴管理は別記事のスコープです。
詰まった場合
- 引数なしで実行すると使い方が表示されます。
- 日本語が文字化けする場合はターミナルの文字コードが UTF-8 になっているか確認してください。
- タイムアウトする場合は
.envのOLLAMA_TIMEOUT_SECONDSを大きくしてみてください。CPU 実行や初回のモデル読み込みでは 120 秒を超えることがあります。 - 応答待ちが長すぎて切り分けしにくい場合は、一時的に
.envのOLLAMA_MODELをqwen3.5:0.8bかqwen3.5:2bに切り替えて疎通確認し、配線が確認できたらqwen3.5:4bに戻してください。
コードのポイント
① $_ENV で OllamaClient に設定値を渡す
vlucas/phpdotenv の createImmutable を使うと、.env の値が $_ENV 経由で参照できます。名前付き引数で渡すことで、コンストラクタの引数順を気にせず読みやすくなります。OLLAMA_TIMEOUT_SECONDS は文字列で入るため (int) キャストを明示しています。
$client = new OllamaClient(
baseUrl: $_ENV['OLLAMA_BASE_URL'],
model: $_ENV['OLLAMA_MODEL'],
timeoutSeconds: (int) $_ENV['OLLAMA_TIMEOUT_SECONDS'],
);② エラーを STDERR へ出力して終了する
fwrite(STDERR, ...) で標準エラー出力に書くことで、エラーメッセージとモデルの応答本文が混在しません。exit(1) で非ゼロの終了コードを返すため、シェルスクリプトや CI で異常終了を検知できます。
} catch (\RuntimeException $e) {
fwrite(STDERR, "Error: {$e->getMessage()}\n");
exit(1);
}7. 応答 JSON と失敗時処理の見方を整理する
動いたあとに「どのキーを見ればよいか」「どこで失敗するか」を整理します。
応答 JSON の主要フィールド
stream:false で返る単一 JSON の主要フィールドです。
| フィールド | 型 | 内容 |
|---|---|---|
model | string | 使用されたモデル名 |
response | string | モデルの出力本文 |
thinking | string | thinking を有効にした場合の reasoning trace |
done | bool | 生成が完了したかどうか |
done_reason | string | 完了理由("stop" など) |
total_duration | int | 処理全体の所要時間(ナノ秒) |
load_duration | int | モデル読み込みの所要時間(ナノ秒) |
eval_count | int | 生成されたトークン数 |
eval_duration | int | トークン生成の所要時間(ナノ秒) |
response だけ見れば最小構成としては十分です。done や done_reason を知っておくと、後で生成の打ち切り判定などに使えます。thinking は think:true のときに別扱いしたくなった段階で見れば十分です。
stream:false を外すと、応答は ndjson(改行区切りの JSON)になり、1 トークンごとに {"response":"...","done":false} が送られてきます。扱い方がまったく異なるため、本記事では固定しています。
エラー切り分け表
| 症状 | 原因の候補 | 確認方法 |
|---|---|---|
cURL error: Connection refused | Ollama が起動していない | ollama serve で手動起動する |
cURL error: Operation timed out | モデル読み込みや推論に時間がかかっている | OLLAMA_TIMEOUT_SECONDS を増やす。初回はモデル読み込みで時間がかかる |
HTTP 404 | エンドポイントの URL が間違っている | .env の OLLAMA_BASE_URL を確認する |
HTTP 400 / model not found | モデル名が間違っている | .env の OLLAMA_MODEL と ollama list の表記を照合する |
JSON decode failed | 受信した body が JSON でない | 3 章のホスト側確認に戻り、API の応答を直接確認する |
'response' key missing | API の応答形式が想定と異なる | stream:false が付いているか確認する。付け忘れると ndjson になる |
thinking が前提の応答になって扱いにくい | thinking を有効にしたまま呼んでいる | think:false を付ける |
接続失敗とモデル出力の失敗は分けて見るのが基本です。接続できているのに応答が想定外なら、まず 3 章のホスト側確認に戻るのが近道です。
ログとプロンプトの扱い
エラーログや例外メッセージにプロンプトの全文を含めないようにしてください。プロンプトにはユーザーの入力がそのまま入るため、機微情報が含まれる可能性があります。
OllamaClient のエラーメッセージに HTTP ステータスや接続先だけを含めているのは、この配慮によるものです。
localhost と host.docker.internal
| 場所 | 使う URL |
|---|---|
| ホスト側(Windows / WSL)から確認する場合 | http://localhost:11434/api/generate |
| コンテナ内の PHP から呼ぶ場合 | http://host.docker.internal:11434/api/generate |
コンテナ内の localhost はコンテナ自身を指すため、ホスト側の Ollama にはつながりません。host.docker.internal は Docker Desktop が提供するホストマシンへの参照です。
この前提は Docker Desktop 向けなので、Linux サーバー上の素の Docker Engine へそのまま持ち込むときは接続方法を見直してください。
8. まとめと次の一歩
到達した状態:
- Ollama に
qwen3.5:4bを用意し、ローカル API が動くことを確認した - PHP の
ext-curlでPOST /api/generate(stream:false)を呼び、単一 JSON として応答を受け取った responseフィールドから本文を取り出し、接続失敗・タイムアウト・HTTP エラー・JSON 破損を分岐した
最小構成としてはここまでで十分です。
次に広げる場合、以下が候補です。
- Slim 4 の route へ組み込む — CLI スクリプトを Web API として公開する
- structured outputs を足す —
format: "json"や JSON Schema でモデルの出力形式を制御する - streaming を扱う —
stream:trueで ndjson を逐次受信し、リアルタイム表示に対応する